
Most sentiment tools score messages in a vacuum.
A 🔥 emoji is positive. "down bad" is negative. Done.
That's why their scores feel wrong.
Here's everything Vibewatch knows about a message before it ever assigns it a number.
The problem with scoring in a vacuum
Take a message like "finally". Is that relief that a long-broken bridge is back up? Sarcasm at a feature you've been promising for six months? Or someone replying to a meme that has nothing to do with you?
Same word. Three completely different scores.
Most tools just look at the text. They run it through a model trained on tweets and reviews, spit out a number, and call it a day. No wonder community managers don't trust the output. The tool isn't wrong because the model is bad — it's wrong because it doesn't know anything about your community when it makes the call.
This is why every dashboard you've tried feels like it's scoring someone else's audience. Because in a real sense, it is.
Vibewatch doesn't guess. Before any message gets a sentiment score, five layers of context get attached to it. Some of them come from your account setup. Some of them come from the message itself. And some of them come from corrections you've already made — feedback the tool has folded into how it reads your community.
What Vibewatch knows before it scores
It knows your brand.
Every scoring pass starts with your brand description — what you ship, who you serve, the language your community actually uses. So when someone says "the bridge is finally back", Vibewatch reads that as relief about a known outage, not as a generic phrase. Your project's vocabulary, your in-jokes, the things your community cares about — all of it is loaded in before a single message is read.
It knows your corrections.
When you fix a miscategorized message in Vibewatch, that correction doesn't just update one row in a database. It becomes a worked example for the next round of scoring — the system literally sees you said this was a 4, the user said it should be an 8, here's why. Your judgment, not a generic baseline trained on Amazon reviews from 2018, becomes the calibration target.
And the more you correct, the more it adds up. Vibewatch periodically distills your accumulated corrections into qualitative rules for your specific community — things like "sarcastic praise about gas fees should score lower than it reads" or "complaints about the docs are usually high-relevance, not noise". Only the rules with high confidence get applied. Over time, your taste becomes house style. The tool starts scoring the way you would.
It knows the conversation.
A reply isn't a standalone message.
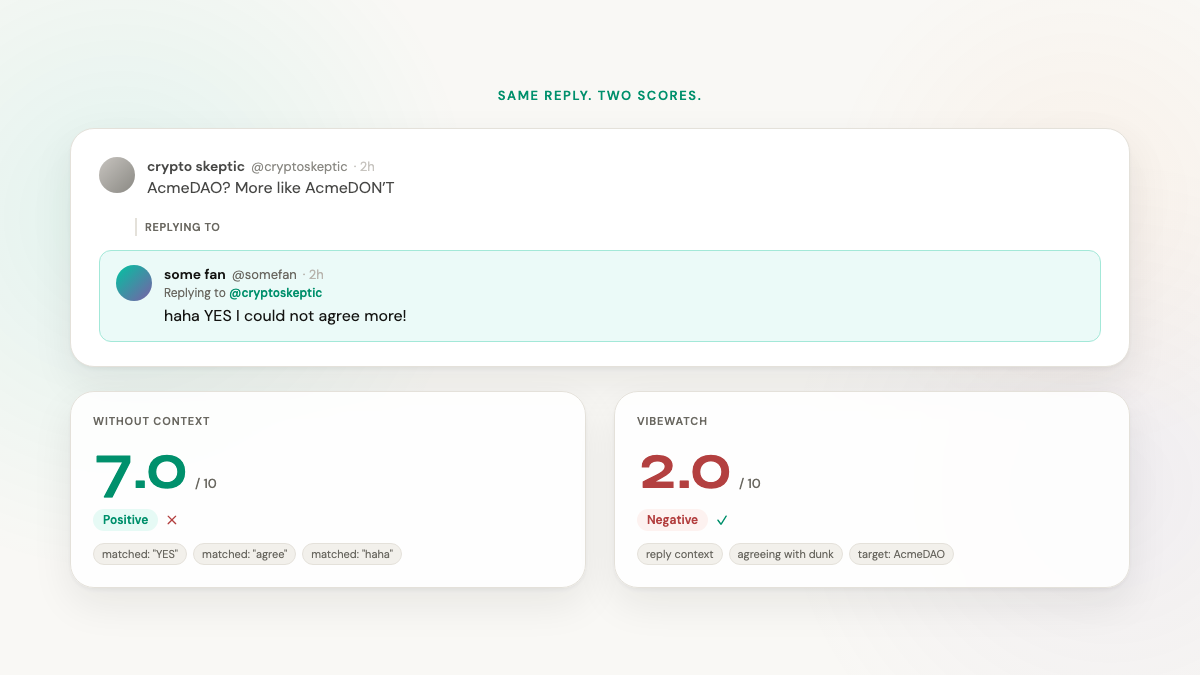
Take "haha YES I could not agree more!" — a traditional sentiment tool reads the words, sees the enthusiasm, scores it around a 7. Easy.
But what if the parent message was "AcmeDAO? More like AcmeDON'T"? Now that reply is enthusiastically agreeing with a dunk on you. The right score isn't a 7. It's a 2.
Vibewatch attaches the parent message — and who wrote it — to every reply before it scores. That same enthusiastic "YES I could not agree more!" gets read in the context of what it's replying to, and the score flips the right way.
It knows the media.
GIFs, stickers, and image-only posts aren't blanks. People say a lot with a single sticker, and any tool that just sees "[image]" is throwing away half your community's signal.
Vibewatch reads the alt text, sticker names, filenames, and other media context that platforms expose. So a sticker named "this is fine fire dog" doesn't get scored as a 5/10 neutral — it gets read for what it actually is.
It knows when you're being talked around, not to.
On X especially, your handle gets pulled into long reply chains where someone is mainly arguing with someone else and you got tagged on the way through. That's a very different situation than someone speaking directly to you.
Vibewatch tags those passive mentions and treats them differently. Direct mentions stay high-relevance. "You got dragged into someone else's fight" stays low-relevance — so it doesn't dominate your dashboard or pull your weekly report off-center.
Why this changes the math
Five layers of context don't just produce a more accurate score. They produce a defensible one.
When you show your sentiment chart to leadership, you're not waving a black box. You can click into any single message and explain exactly why it scored what it did — what your community is, what conversation it was part of, what your team has corrected before. That's the difference between "the AI said so" and "here's what's actually happening."
It's also what makes the number useful for triage. A 2/10 sentiment score on a passive mention in someone else's argument is not the same fire drill as a 2/10 on a direct reply from a power user — and your dashboard knows the difference.
And because the system learns from every correction you make, the scores get more yours every week. Not more generic. Not regressing to some industry mean. Yours.
That's what it takes to actually trust the number.
Open beta is live
We've been in closed beta for months and stress-tested with communities of 200k+ members. Every score in your dashboard runs through every layer above.
Plans start at $19/mo. Your first weekly report is on us.
Start your free trial at vibewatch.io.